Table Partitioning in PostgreSQL
17 Aug 2015
If you’re familiar with Postgres, you’re probably already aware it has a fantastic table inheritance feature, whereby child tables can derive columns from parent tables. What you may not know is this is also the primary feature that enables table partitioning. Unfortunately, the official docs provide a fairly simplistic example of how to go about implementing it. This post provides a real world partitioning example, and some of the gotcha’s you may encounter.
Update 2018–01–20: PostgreSQL 10 has added table partitioning, making this article obsolete.
Problem Statement
Consider a hypothetical comments table:
CREATE TABLE “comments” (
id uuid DEFAULT uuid_generate_v4() NOT NULL,
user_id uuid NOT NULL,
comment text,
created_at timestamp with time zone DEFAULT now() NOT NULL,
modified_at timestamp with time zone DEFAULT now() NOT NULL
);
The table is expected to grow at a rate of a few million new rows per month. Fairly soon, performance will suffer. You observe the queries run by the application utilize the created_at column, and decide to use the month and year for partitioning the table.
Partitioning Strategy
Upon INSERT, new comments will be routed to a comments_
For example, take the following INSERT:
INSERT INTO comments
(user_id, comment, modified_at, created_at)
VALUES
(‘fe4742c7–909e-4df2–84fc-03d40372f224’, ‘Hello World’, ‘2016–07–01 18:50:59–00’, ‘2016–07–01 18:50:59–00’);
Based on its created_at date, this row will be inserted into the comments_2016_07 table. Comments inserted for the next month would be routed to comments_2016_08, and so forth. Barring a huge surge in the app’s popularity, this should keep each table’s row count in a comfortable range.
Goals
With our strategy in hand, we can set some objectives:
- From the application code’s standpoint, there should be no changes necessary; partitioning should be transparent.
- Minimal administration necessary; when a new INSERT is routed to a table that doesn’t exist, the table should be created automatically.
- After UPDATING, INSERTING, or DELETING, the RETURNING clause should continue to work as per usual (again, see goal #1).
- Upon creation, child tables should be given proper indexes.
Implementation
First, an overview of the steps:
- Create a table called comments_base. All child tables will inherit from this base table.
- Create a view called comments. The application will perform all CRUD operations using this view. The application should ignore the existence of comments_base and all child tables.
- Create a function which routes inserts to comments to the appropriate child table.
Creating the base table
CREATE TABLE comments_base (
id uuid DEFAULT uuid_generate_v4() NOT NULL,
user_id uuid NOT NULL,
comment text,
created_at timestamp with time zone DEFAULT now() NOT NULL,
modified_at timestamp with time zone DEFAULT now() NOT NULL
);
Think of the base table as providing the column template from which all child tables will be derived. Excepting indexes, a child table’s definition comes exclusively from the base table.
Create the view
CREATE VIEW comments AS SELECT * FROM comments_base;
This view replaces the original comments table. You might choose to rename the original comments table to comments_base, or dump the data for insert later and simply drop.
As mentioned above, the application will perform all SELECTS, INSERTS, UPDATES and DELETEs on the view.
Create a routing function
CREATE OR REPLACE FUNCTION
public.insert_comment()
RETURNS TRIGGER AS
$BODY$
DECLARE
_start_dt text;
_end_dt text;
_table_name text;
BEGIN
IF NEW.id IS NULL THEN
NEW.id := uuid_generate_v4(); -- or using auto incrementing: NEW.id := nextval('comments_id_seq');
END IF;
-- determine table name the insert should be routed to
_table_name := 'comments_' || to_char(NEW."created_at", 'YYYY_MM');
-- Does the partition table already exist?
PERFORM 1
FROM pg_catalog.pg_class c
JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND c.relname = _table_name
AND n.nspname = 'public';
-- If not, create it before continuing with the insert
IF NOT FOUND THEN
-- start_dt determines the earliest records allowed in the table, using the beginning of the month e.g. >= 2016-01-01 00:00:00
-- end_dt determines the oldest records allowed in the table, using the beginning of the next month e.g. < 2016-02-01 :0000:00
_start_dt := to_char(date_trunc('month', NEW."created_at"), 'YYYY-MM-DD');
_end_dt:=_start_dt::timestamp + INTERVAL '1 month';
EXECUTE 'CREATE TABLE public.' || quote_ident(_table_name) || ' (
CHECK ( "created_at" >= ' || quote_literal(_start_dt) || '
AND "created_at" < ' || quote_literal(_end_dt) || ')
) INHERITS (public.comments_base)';
-- Indexes are not inherited from the parent
EXECUTE 'CREATE INDEX ' || quote_ident(_table_name||'_created_at_idx') || ' ON public.' || quote_ident(_table_name) || ' (created_at)';
-- Set table permissions
EXECUTE 'ALTER TABLE public.' || quote_ident(_table_name) || ' OWNER TO ' || quote_ident(current_user);
EXECUTE 'GRANT ALL ON TABLE public.' || quote_ident(_table_name) || ' TO ' || quote_ident(current_user);
END IF;
EXECUTE 'INSERT INTO public.' || quote_ident(_table_name) || ' VALUES ($1.*) RETURNING *' USING NEW;
RETURN NEW; -- Allows RETURNING to work
END;
$BODY$
LANGUAGE plpgsql;
-- Intercept the INSERT, relying on the insert_comment() function to route the row to the appropriate table
CREATE TRIGGER comments_insert_trigger
INSTEAD OF INSERT ON public.comments
FOR EACH ROW EXECUTE PROCEDURE insert_comment();
Validation
Now, when we try our previous INSERT, a table is automatically created to house the new record:

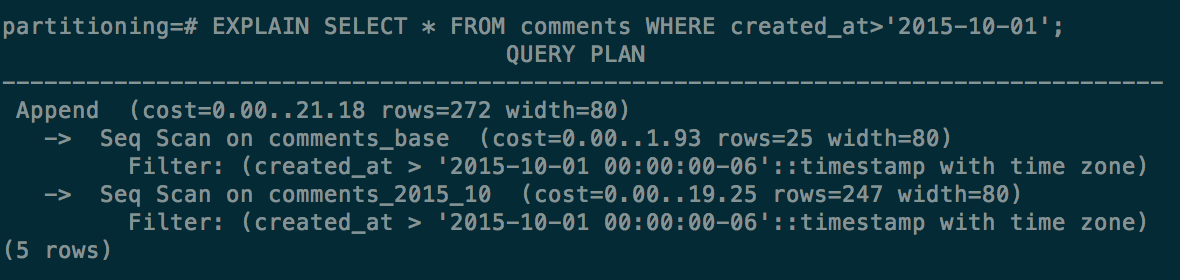
Try a few EXPLAIN queries and observe how the CHECK constraints allow the query optimizer to eliminate scanning certain child tables.
Selecting all rows(includes every child table):
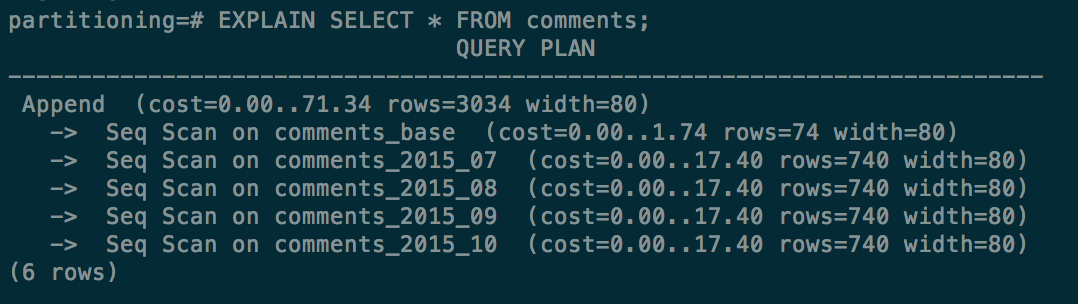
vs with a WHERE clause on created_at (eliminates tables 07-09):
Gotchas, oops, etc.
Changing created_at
Let’s say you wanted to UPDATE a record’s created_at for some reason. You’ll receive a check constraint error, because the record will no longer meet the constraint condition:

In this situation all is not lost; you could certainly DELETE and re-INSERT(if you do, use a transaction!). However, be aware that if your application is going to be performing queries like the one above, your partitioning strategy is going to make things complicated…consider re-evaluating your partitioning strategy.
INSERTs with nowhere to go
Pay close attention to lines 32 & 33 in the gist above — notice the inclusive condition on start_dt(>=), and the exclusive condition on end_dt(<). Suppose you chose an exclusive condition for both — INSERTs with created_at’s falling between those values would fail, since no table would accept them.
Additional Reading
scaling postgresql performance using table partitioning
postgres trigger-based insert redirection without breaking RETURNING